
티스토리 뷰
배경.
배치를 만들던 도중에 Bean으로 등록해놓은 Thread Pool에 Thread가 꽉차서 Queue에 더 이상 Job이 들어갈 수 없다는 예외가 발생했습니다. 예를 들기 위해 테스트 코드를 하나 작성해보겠습니다.
class ThreadPoolExecutorTest {
@Test
fun testThreadPoolQueueCapacity() {
val executor = ThreadPoolExecutor(
2, // core pool size
2, // max pool size
0L, // keep alive time
TimeUnit.MILLISECONDS, // time unit for keep alive time
LinkedBlockingQueue(1) // queue with capacity 1
)
Assertions.assertThrows(RejectedExecutionException::class.java) {
for (i in 1..4) {
executor.submit {
try {
println("Task $i started")
Thread.sleep(5000)
println("Task $i completed")
} catch (e: InterruptedException) {
e.printStackTrace()
}
}
}
}
executor.shutdown()
}
}RejectedExecutionException이 발생하는 예시입니다.
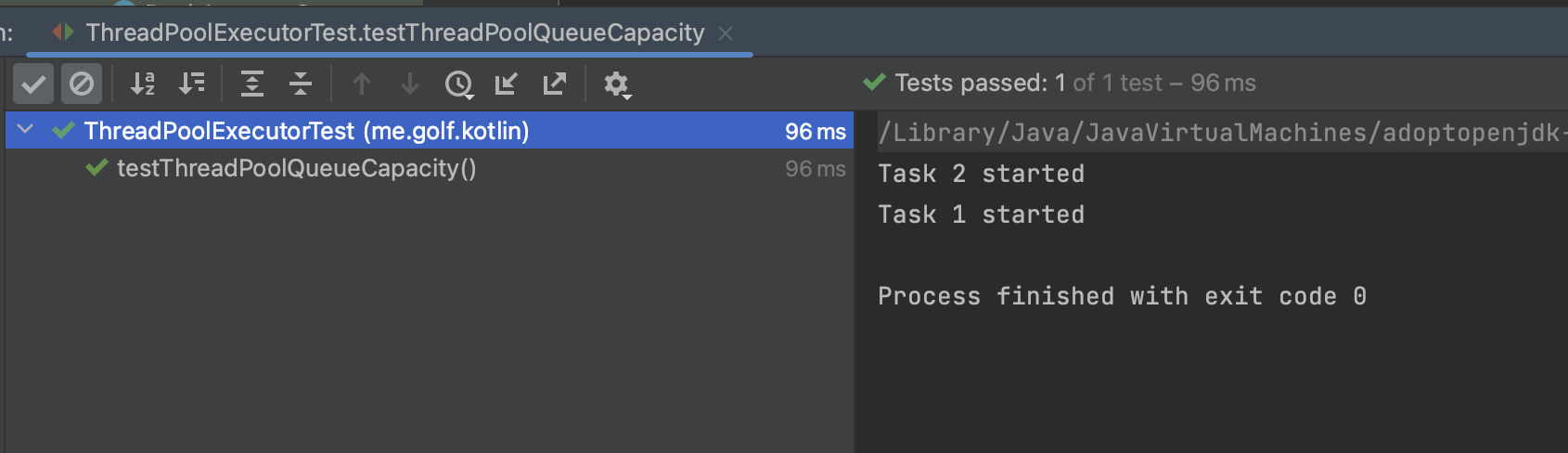
그렇다면 이 문제를 어떻게 해결해야할까요 ? 해결하기 전에 Thread Pool에서 작업들을 어떻게 관리하는지 알아봅시다.
Thread Pool과 Wait Queue
Thread Pool에 모든 스레드가 사용 중인데 요청이 계속들어올 수 있습니다. 그리고 이거를 wait queue에 담아 대기 시키는데요. 이 때 Java에서는 Blocking Queue에 담아 처리하고 있습니다. 대표적으로 Executors.newFixedThreadPool을 살펴보면

내부적으로 LinkedBlockingQueue 를 사용하여 모든 스레드들이 사용중일 때 대기할 수 있는 Queue를 만듭니다.
이걸 그림으로 표현하면 이렇습니다.

Main thread가 작업을 생성하여 Queue에 전달하고 Queue에 담겨있는 Job 들은 현재 사용하지 않는 Thread가 존재하면 Pool에서 Thread에게 할당 되어 처리됩니다.
위 테스트에서 Exception이 발생한 이유는 Main Thread가 계속해서 작업을 생산하여 Thread 들에게 전달해주어야 하는데 Blocking Queue 공간과 Thread 자원을 모두 사용 중이라 더 이상 작업을 받지 못해 발생한 에러 입니다.
🤔 해결하기 위한 방법 2가지
본 글에선 문제를 해결할 때 사용한 두 가지 방법을 소개 드릴 예정입니다.
- Blocking Queue Size 늘리기
가장 간단한 해결 방법입니다. Queue의 capacity size를 늘려 더 많은 Job 들이 대기할 수 있게 해줍니다. 하지만 이 방법은 작업 지연 시간이 늘어나며 메모리 사용량이 크게 늘어날 수 있습니다. 서버 상황을 고려하여 늘려주어야 합니다. - CallerRunsPolicy 전략을 이용하기
rejected execution handler로 설정을 통해 처리하는 방법입니다. CallerRunsPolicy 전략은 스레드 풀 작업 처리 능력을 초과하는 작업이 제출될 때, 작업을 생산한 스레드가 해당 작업을 처리하게 합니다. 이 경우 스레드 풀의 작업 능력을 초과하더라도 작업이 계속 처리됩니다.
결론적으로 메모리 사용량을 크게 사용하지 않으면서 처리가 가능합니다. 다만 이 경우에 작업을 생산한 스레드가 직접 처리하고 다시 생산을 해야하기 때문에 작업 속도가 느려질 수 있습니다.
코드를 보면 다음과 같습니다.
class ThreadPoolExecutorTest {
@Test
fun testThreadPoolQueueCapacity() {
val executor = ThreadPoolExecutor(
2, // core pool size
2, // max pool size
0L, // keep alive time
TimeUnit.MILLISECONDS, // time unit for keep alive time
LinkedBlockingQueue(1) // queue with capacity 1
)
// CallerRunsPolicy 전략 사용
executor.rejectedExecutionHandler = ThreadPoolExecutor.CallerRunsPolicy()
for (i in 1..4) {
executor.submit {
try {
println("Task $i started")
Thread.sleep(5000)
println("Task $i completed")
} catch (e: InterruptedException) {
e.printStackTrace()
}
}
}
executor.shutdown()
}
}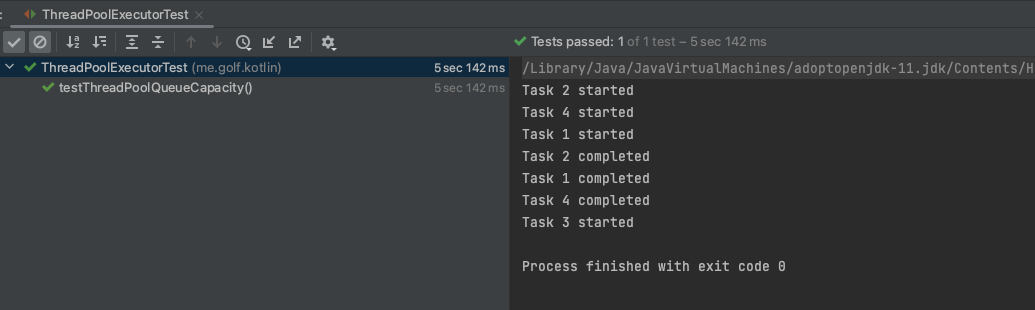
정상적으로 처리가 된 걸 볼 수 있습니다.
반대로 그럼 Blocking Queue Size를 키워보겠습니다.
class ThreadPoolExecutorTest {
@Test
fun testThreadPoolQueueCapacity() {
val executor = ThreadPoolExecutor(
2, // core pool size
2, // max pool size
0L, // keep alive time
TimeUnit.MILLISECONDS, // time unit for keep alive time
LinkedBlockingQueue(10) // queue with capacity 10 Increase
)
// executor.rejectedExecutionHandler = ThreadPoolExecutor.CallerRunsPolicy()
for (i in 1..4) {
executor.submit {
try {
println("Task $i started")
Thread.sleep(5000)
println("Task $i completed")
} catch (e: InterruptedException) {
e.printStackTrace()
}
}
}
executor.shutdown()
}
}
결론
저는 위 두 가지 방법 모두를 사용해서 해결했습니다. 큐 사이즈도 늘리고 만에하나 제가 예상한 큐 사이즈 보다 많은 요청량이 들어오더라도 예외가 발생하지 않고 계속 처리될 수 있도록 말입니다. 그리고 모니터링을 통해서 혹시나 해당 API가 느려지면 바로 alert을 확인할 수 있게 slack에 경보를 연동시켜놓았기 때문에 바로 대응이 가능한 상황이었습니다.
위 두 방법에 대해 설명 드렸지만 외에도 여러 해결 방법이 있을 수 있습니다. 만약 이메일 푸시 알람 같은 비즈니스 로직에 벗어나는 동작들은 비동기나 ExceptionHandling 으로 해결할 수 있죠.
또한 더 엄청난 양의 요청을 처리해야한다면 kafka, rabbitMQ 같은 Message Queue 등을 고려할 수 있겠습니다.
마침.
'Java' 카테고리의 다른 글
| OOM이 발생했을 때 어버버 하지 않게 대비하기! (1) | 2023.09.27 |
|---|---|
| GC에서 stop the world를 하는 이유가 뭘까? (0) | 2023.04.22 |
| 비동기가 동기 보다 좋은 경우가 무엇일까? (WebFlux와 MVC를 예시로) (0) | 2023.03.21 |
| 스레드 풀이 없으면 자바에서 왜 Thread 생성 비용이 늘어날까? (4) | 2023.03.20 |
| hashTable vs synchronizedMap vs ConcurrentHashMap (0) | 2023.03.16 |
- Total
- Today
- Yesterday
- Spring
- 면접
- 코드
- 취준
- 인터뷰
- DevOps
- CS
- 개발
- 게시판
- 자바
- 코딩
- JPA
- thread
- docker
- IT
- 프로그래밍
- Redis
- java
- 면접 준비
- 프로젝트
- 취업
- lock
- 면접준비
- MySQL
- 동시성
- Kotlin
- 취업준비
- DB
- 백엔드
- 개발자
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |