
티스토리 뷰
배경
회사에서 7만개 혹은 11만개의 데이터를 외부에서 받아와 대량으로 전송해야하는 배치 프로그램을 개발 중이었습니다. 처음엔 FeignClient를 사용하여 개발 하였습니다. 하지만 단일 스레드로는 성능이 너무 나오지 않아 11번 호출해서 데이터를 받아오는데에도 오랜시간이 소요되었습니다. 만약 7만개 이상의 데이터를 가져오려면 너무 오랜 시간 동안 배치가 실행되어야 했고, 그러면 다른 배치들과 겹쳐서 돌아가기 때문에 서버에 큰 부담이 생기거나 제가 올린 배치 때문에 병목 현상이 생기는것도 고려해야했습니다.
🤔 멀티 스레드를 사용한다면?
처음에 이 문제를 해결 하기 위해서 저는 멀티 스레드를 사용했습니다. Executor를 Bean으로 등록하고 서비스에서 주입 받아 사용했습니다.
@Service
@RequiredArgConstructor
public class ClientService {
private final SomethingFeignClient somethingFeignClient;
private final Executor excutor
public void getData(List<String> paths) {
CountDownLatch latch = new CountDownLatch(paths.size); // 요청 보내는 수 만큼 모아서 처리
List<Dto> bodyData = new ArrayList<>();
for (String path : paths) {
excutor.submit(() => {
bodyData.add(somethingFeignClient.getData(path));
latch.countDown();
});
}
latch.await(); // 작업 끝난 thread 대기
somethingFeignClient.sendData(bodyData);
}
}위 코드는 멀티 스레드를 적용했습니다. 10개의 스레드를 사용하여 동시 처리를 하여 성능을 올렸습니다. 하지만 그럼에도 현재 병목현상을 없앨 만할 처리 속도가 나오지 않았습니다. 실제로 테스트 해봤을 때 이 애플리케이션의 성능은 7번의 호출 기준 최대 12초가 나왔습니다. 7만개의 데이터라면 엄청 오랫동안 처리 했을거라고 예상됩니다. 그렇다면 자원을 더 늘린다면 어떨까요? 성능은 비약적으로 상승할지 몰라도 그 만큼 많은 자원을 사용하게 될 것이고 이는 전체 서버의 병목 현상을 발생시킬 수 있습니다.
🤔 자원을 아끼면서 성능을 개선할 수 있는 방법은 없을까?
자원을 계속 늘리는 것은 결국 큰 해결책이 되지 못했습니다. 왜 해결책이 되지 않았을까요? 그건 바로 Feign Client의 동작 방식 때문입니다. Feign Client는 Blocking I/O 방식이기 때문에 Thread가 요청을 보내면 다른 작업을 하지 않고 요청을 받아올 때 까지 기다려야합니다. 그렇기 때문에 스레드를 기하급수적으로 늘려야 많은 데이터 처리 시 효과를 볼 수 있는 것입니다.
그래서 필자는 non-blocking I/O를 지원해주는 webClient를 도입하였습니다. non-blocking I/O는 스레드가 요청을 보내고 다음 응답을 기다리는 방식이 아닌 다른작업을 하러 갑니다. 그렇기 때문에 적은 자원으로도 동시에 Blocking I/O 보다 많은 데이터 처리가 가능합니다.
Blocking I/O방식과 Non-Blocking 방식을 그림으로 살펴보면 다음과 같습니다.
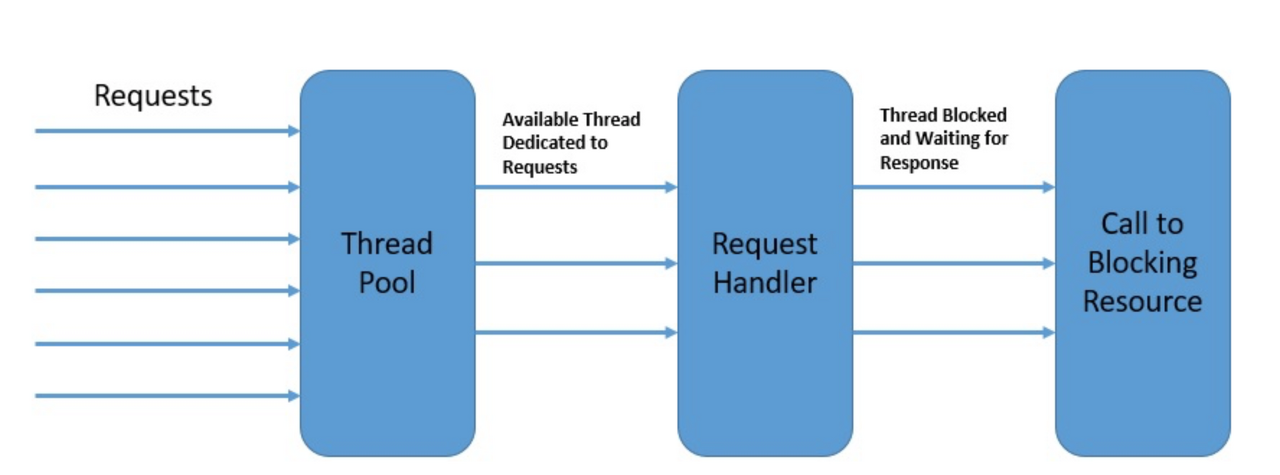

이벤트 루프는 요청을 받고 처리하여 publisher에 전달합니다. 그러고 또 다른 요청을 처리하고 이를 반복합니다. 그리고 처리 중간에 요청에 대한 응답이 오면 처리하고 다시 다른 작업을 합니다.
이러한 방식을 사용했을 때 실제로 7번의 호출 만으로 12초가 나오던 성능이 2초까지 개선 되었으며 7만개의 데이터를 받아오는데 5개의 스레드로 11s 안에 처리가 가능해졌습니다.
그렇다면 간단한 사용법에 대해서 살펴보겠습니다.
⚙️기본 셋팅
모든 설정 값에 -1은 제한 없음을 의미합니다.
public WebClientImpl() {
ConnectionProvider provider = ConnectionProvider.builder("client")
.maxConnections(-1) // 서버 상황을 고려하여 설정
.pendingAcquireMaxCount(-1) // 서버 상황을 고려하여 설정
.pendingAcquireTimeout(Duration.ofSeconds(20))
.maxIdleTime(Duration.ofSeconds(5))
.maxLifeTime(Duration.ofSeconds(5))
.build();
this.httpClient = HttpClient.create(provider);
}maxConnection() : 최대 연결 개수를 설정합니다. Reactive 상황에서는 thread pool이 아니라 한정된 thread 자원들이 지속적으로 작업하고 있기 때문에 connection pool과는 다릅니다.
pendingAcquireMaxCount() : maxConnection의 개수가 이미 초과한 상태이면 queue에서 요청을 대기 시키는데 이 때 size를 의미합니다.
pendingAcquireTimeout() : 대기 queue에서 maxconnection을 점유하기 위해 대기하는 최대 시간을 설정합니다. 해당 시간이 지났는데도 점유하지 못하면 fail이 발생합니다.
maxIdleTime() : 사용 안하는 상태의 Connection 유지되는 시간을 설정합니다.
maxLifeTime() : Connection 상태에서의 최대 유지 시간을 설정합니다.
서버 상황에 맞게 고려하여 세팅을 하는게 좋습니다. 대용량 처리를 하고 있는 애플리케이션에 경우 pendingQueue에 너무 많은 작업이 쌓여버리면 그것도 메모리를 많이 사용하는 것이기 때문에 적당한 connection과 pendingQueue 사이즈를 조절하고 차라리 스레드 개수나 read timeout을 이용하여 부담을 줄여주는 것이 좋습니다.
🏃♂️Mono를 활용하여 비동기 호출 만들기
@Override
public Mono<String> getApiConnection(final URI uri) {
return WebClient.builder()
.clientConnector(new ReactorClientHttpConnector(httpClient))
.defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.build()
.get()
.uri(uri)
.retrieve()
.onStatus(HttpStatus::is4xxClientError, clientResponse ->
Mono.error(() -> new CustomException(uri.toString())))
.onStatus(HttpStatus::is5xxServerError, clientResponse ->
Mono.error(() -> new Exception("치명적인 서버 오류입니다.")))
.bodyToMono(String.class);
}clientConnector() : HttpClient 라이브러리 설정부입니다. HttpClient 기반으로 만들어졌기 때문에 HttpClient를 주입해주어 설정을 바꿔줍니다.
defaultHeader() : Header 기본값을 설정해줍니다.
onStatus() : 에러를 핸들링할 수 있게 해줍니다. 현재 코드에서는 400대 에러와 500대 에러를 구분하여 Exception Handling을 해주고 있습니다.
retrieve() : body를 받아 디코딩 해주는 메소드 입니다.
bodyToMono() : 받은 body 데이터를 Mono로 전환해줍니다. Flux나 Entity로도 받을 수 있으며 Mono나 Flux로 받으면 subscribe를 하지 않는 이상 아무일도 일어나지 않습니다.
자, 이제 그럼 실제 서비스에서 수 백번 같은 호출을 하는 api를 개발할 때 이 개념을 어떻게 이용하는지 알아보겠습니다.
❗️Flux를 이용한 여러번 호출
Mono와 다르게 Flux는 다수의 건을 처리할 때 사용됩니다. Flux를 이용하여 여러번 호출한 후 모아진 Data를 Stream API를 이용하여 Lazy하게 처리하는 배치를 개발해보겠습니다.
private List<String> getResult(List<URI> urls) {
return Flux.fromIterable(urls)
.parallel()
.runOn(Schedulers.fromExecutor(executor))
.flatMap(WebClient::getApiConnection)
.ordered(String::compareTo)
.toStream()
.collect(Collectors.toList());
}parallel() : 레일을 나누어 작업을 병렬로 처리합니다.
runOn() : 스레드풀을 기반으로 실행할 수 있는 기능을 제공해주는 메서드 입니다.
ordered() : 비동기 논블라킹이기 때문에 순서가 보장되지 않습니다. 순서를 보장하기 위해 Flux에서 제공해줍니다.
toStream() : 성능을 개선하면서 핵심이 되는 메서드입니다. 받아온 데이터를 받아와 Stream에 저장하고 이 후 stream api로 데이터를 가공할 수 있습니다. 데이터를 모아서 보내줘야하는 특별한 요구사항일 때 사용하면 효과적입니다.
❓toStream()을 쓰게된 이유
처음 부터 이렇게 사용하려던 것은 아니었습니다. 기존에는 for문으로 Mono를 여러번 호출하여 subscribe를 하여 처리하였었습니다. 이 때 문제는 ArrayList에 값을 넣을 때 발생했습니다. ArrayList는 동기화를 하지 않습니다. 그렇기 때문에 subscribe 블록 안에서 공유 자원인 ArrayList를 두고 여러 thread가 작업하는 것은 동시성 문제를 발생할 가능성이 높았습니다.
그렇다면 지금 필요한건 외부 api 호출을 non-blocking 기반으로 빠르게 가져오고 값을 리스트로 바로 반환하여 thread safe 한 코드를 만들어줘야합니다.

toStream으로 받아온 데이터를 stream으로 만들어 선언형으로 데이터를 가공해 List를 만들어주는 방식을 사용하여 데이터 정합성을 지켜주었습니다.
또한 데이터를 하나도 보내지 못하거나 다 보내거나 연산의 일관성을 지킬 수 있기 때문에 데이터를 모아 보내주어야하는 고객사의 요청에도 알맞는 요구사항이었습니다.
요약
webClient는 non-blocking 방식의 고성능 외부 통신을 제공해줍니다. 하지만 서버의 상태나 처리량에 따른 사이드 이펙트를 꼭 고려해보시기 바랍니다. pending Queue에 작업이 무한히 쌓인다면 이로 인해 서버 병목이 발생할 수 있으며 순서가 매우 중요한 요구사항이라면 flatMap으로 처리가 가능하나 순서 핸들링 자체가 제한적이라면 성능이 떨어지더라도 순차적으로 처리하는 동시 Blocking 방식이 좋을 수 있습니다.
또한 Trade off를 꼭 고려해보시기 바랍니다. 제 상황은 Thread가 많아짐으로 메모리 자원을 많이 사용하는걸 해결하기 위함이었습니다. 비동기로 처리한다면 스레드가 독립적으로 계속 다른 작업을 왔다갔다 하기 때문에 Context Switching이 많이 일어납니다. 이는 CPU에 부담을 줄 수 있습니다. 이러한 점도 꼭 고려하시기 바랍니다.
성능과 요구사항을 고려해보고 충분히 쓸 수 있는 상황이라고 판단되면 좋은 성능의 애플리케이션 구현이 가능해질 것입니다. 이상입니다.
https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Flux.html#toStream--
Flux (reactor-core 3.5.1)
projectreactor.io
https://medium.com/@odysseymoon/spring-webclient-%EC%82%AC%EC%9A%A9%EB%B2%95-5f92d295edc0
Spring WebClient 사용법
Spring 어플리케이션에서 HTTP 요청을 할 땐 주로 RestTemplate 을 사용했었습니다. 하지만 Spring 5.0 버전부터는 RestTemplate 은 유지 모드로 변경되고 향후 deprecated 될 예정입니다.
medium.com
'Spring Framwork & JPA' 카테고리의 다른 글
| Thread Local이란? (0) | 2023.01.05 |
|---|---|
| [Redis] redis에서 get 연산이 일어나는 로직에 Transactional을 건다면? (0) | 2023.01.03 |
| Pagination 전략에 대해서 (Page 인터페이스 커스텀하기) (0) | 2022.08.04 |
| Redis 직렬화/역직렬화시 생기는 Issue (0) | 2022.05.23 |
| [Thymleaf - 1부] 타임리프의 주요 문법 (0) | 2022.02.21 |
- Total
- Today
- Yesterday
- 개발자
- 게시판
- CS
- docker
- java
- 코딩
- 면접 준비
- 취업
- lock
- JPA
- 코드
- 개발
- Redis
- 면접준비
- 면접
- MySQL
- thread
- 동시성
- DevOps
- 프로젝트
- 취준
- 백엔드
- DB
- 자바
- Spring
- Kotlin
- 프로그래밍
- 취업준비
- 인터뷰
- IT
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |