
티스토리 뷰
InnoDB는 스토리지 엔진에서 가장 핵심적인 부분이다. 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이고 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할도 같이한다.
일반적인 애플리케이션에서는 INSERT, UPDATE 그리고 DELETE 처럼 데이터를 변경하는 쿼리는 데이터 파일의 이곳 저곳에 위치한 레코드를 변경하기 때문에 랜덤한 디스크 작업을 발생 시킨다. 하지만 버퍼 풀이 이를 모아서 처리하면 횟수를 줄일 수 있다.
버퍼 풀의 구조
InnoDB 스토리지 엔진은 버퍼 풀이라는 거대한 메모리 공간을 페이지 크기의 조각으로 쪼개어 InnoDB 스토리지 엔진이 데이터를 필요로 할 때 해당 데이터 페이지를 읽어서 각 조각에 저장한다. 버퍼 풀의 페이지 크기 조각을 관리하기 위해 InnoDB 스토리지 엔진은 크게 LRU 리스트와 플러시 리스트, 그리고 프리 리스트라는 3개의 자료 구조를 관리한다.
구조를 그림으로 살펴보면 다음과 같다.
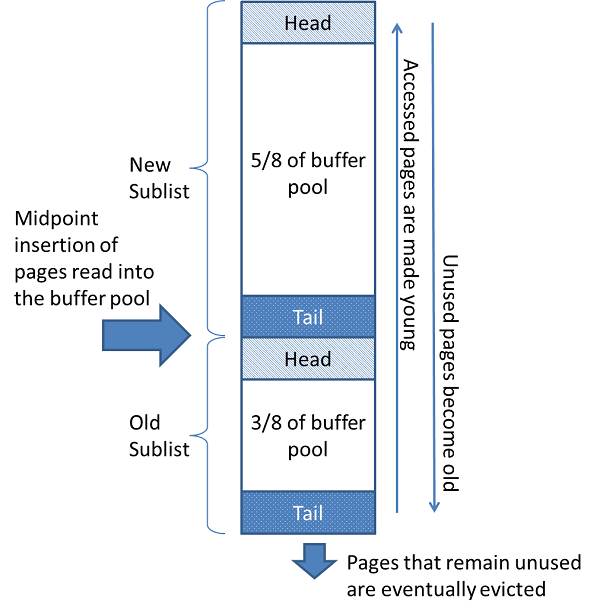
LRU 리스트를 관리하는 목적은 디스크로부터 한 번 읽어온 페이지를 최대한 오랫동안 InnoDB 버퍼 풀의 메모리에 유지해서 디스크 읽기를 최소화하는 것이다. InnoDB 스토리지 엔진에서 데이터를 찾는과정은 대략 다음과 같다.
- 필요한 레코드가 저장된 데이터 페이지가 버퍼 풀에 있는지 검사
- InnoDB 어댑티브 해시 인덱스를 이용해 페이즈를 검색
- 해당 테이블의 인덱스(B-Tree)를 이용해 버퍼 풀에서 페이지를 검색
- 버퍼 풀에 이미 데이터 페이지가 있었다면 해당 페이지의 포인터를 MRU 방향으로 승급
- 디스크에서 필요한 데이터 페이지를 버퍼 풀에 적재하고, 적재된 페이지에 대한 포인터를 LRU 헤더 부분에 추가
- 버퍼 풀의 LRU 헤더 부분에 부분에 적재된 데이터 페이지가 실제로 읽히면 MRU 헤더 부분으로 이동
- 버퍼 풀에 상주하는 데이터 페이지는 사용자 쿼리가 얼마나 최근에 접근했었는지에 따라 나이가 부여되며, 버퍼 풀에 상주하는 동안 쿼리에서 오랫동안 사용되지 않으면 데이터 페이지에 부여된 나이가 오래되고 결국 해당 페이지는 버퍼 풀에서 제거 된다. 버퍼 풀의 데이터 페이지가 쿼리에 의해 사용되는 나이가 초기화가 되어 다시 짊어지고 MRU의 헤더 부분으로 옮겨진다.
그래서 처음 한 번 읽힌 데이터 페이지가 이후 자주 사용된다면 그 데이터 페이지는 InnoDB 버퍼 풀의 MRU 영역에서 계속 살아남게 되고, 반대로 거의 사용되지 않는다면 새롭게 디스크에서 읽히는 데이터 페이지들에 밀려서 LRU의 끝으로 밀려나 결국은 버퍼 풀에서 제거된다.
'CS > DB' 카테고리의 다른 글
| 클러스터링 인덱스 vs 논 클러스터링 인덱스 (1) | 2023.04.21 |
|---|---|
| Index란? (0) | 2022.08.25 |
| 프로젝트에 커버링 인덱스를 적용해볼까? (0) | 2022.07.21 |
| InnoDB 스토리지 엔진 아키텍처 (0) | 2021.11.28 |
| MySQL 아키텍처 (0) | 2021.11.28 |
- Total
- Today
- Yesterday
- 취업준비
- 면접 준비
- 동시성
- 백엔드
- DB
- Redis
- java
- 개발자
- 개발
- 면접준비
- 코딩
- 코드
- thread
- 인터뷰
- 자바
- JPA
- Kotlin
- 취업
- lock
- IT
- DevOps
- MySQL
- CS
- docker
- Spring
- 게시판
- 면접
- 프로그래밍
- 프로젝트
- 취준
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |